论文笔记--Self-Supervised 3D Face Reconstruction via Conditional Estimation
摘要
本文提出一种条件估计的框架,利用自监督学习方式实现从2D单视角图片学习3D人脸参数,该方法简称CEST。CEST是一个综合分析过程,大体上看是从面部图片得到3D面部参数(形状,反射率,视角,光照),根据这些参数重建出2D图片。
在这个过程中,结合3D人脸参数之间的统计相关性来耦合各个参数估计值,具体来说就是某一项参数的估计不仅取决于源图像,也取决于前面已经预测推导出来的参数。此外,本文还利用视频帧之间的反射对称性和一致性来提高人脸参数的解耦。
局限性
训练数据的稀缺;拥有ground-truth的数据集对神经网络的泛化能力提升有限;之前的工作对目标参数(形状,反射率,光照等)都是单独估计的,没有考虑这些参数之间的联系。
创新点
- 提出一种条件估计的网络框架,明确考虑各项三维人脸参数之间的相关性,多项参数(视角,形状,反射率,光照)是依次推导求得。
- 提出了一种随机优化策略,有效地将反射对称性和一致性约束纳入CEST。随着视频帧数的增加,CEST的计算复杂度呈线性增加,而不是二次增加。
方法
整体概览
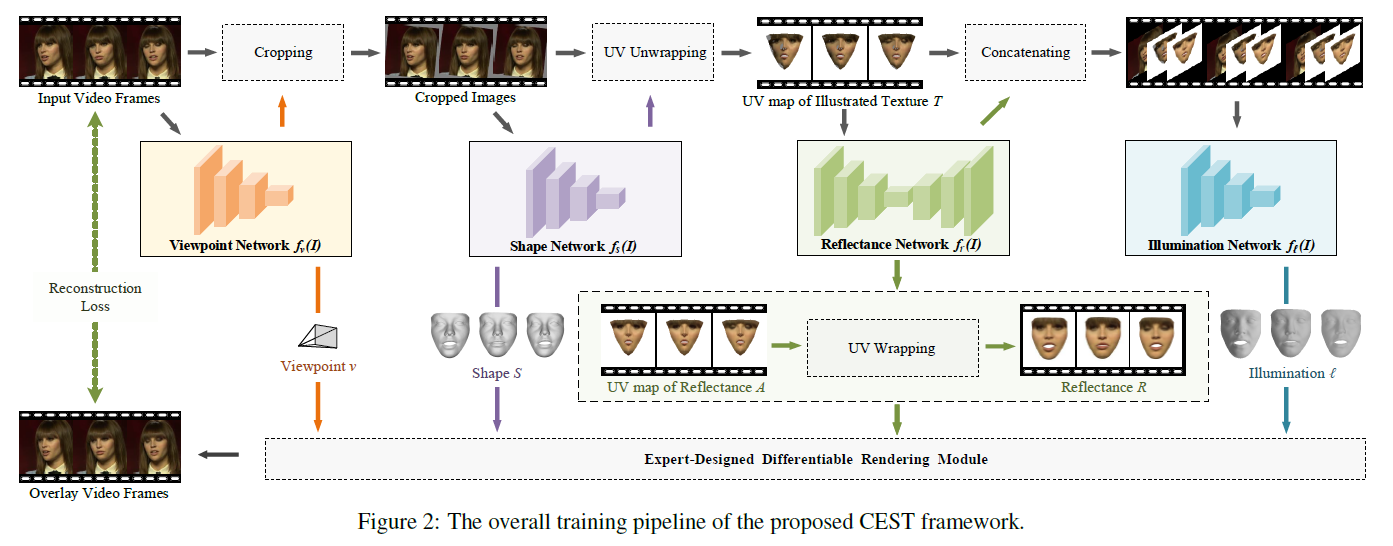
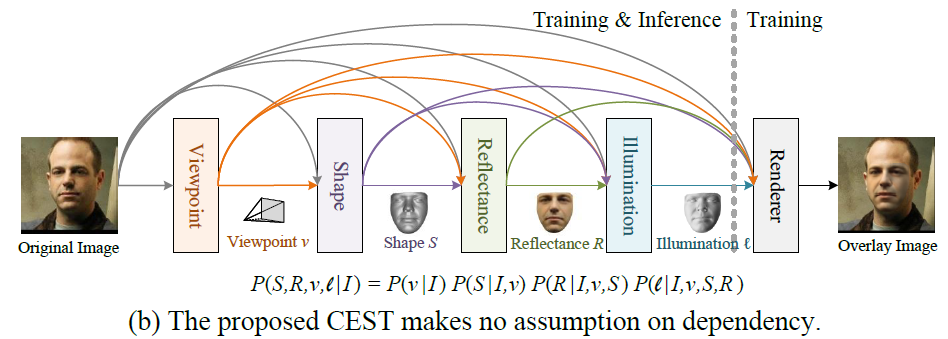
参数估计
与很多拟合3DMM得到重建人脸模型思路相仿,需要先得到形状\(\hat{S}\),视角点\(\hat{v}\),反射率\(\hat{R}\),光照\(\hat{\ell}\)等参数,接着利用这些参数拟合人脸模型,最后通过渲染\(\hat{I}=\mathcal{R}(S,R,v,\ell)\)得到重建2D人脸图片,整个过程都是一个端到端的预测方式。各项参数获取公式如下:
\[ \hat{v}=f_v(I;\theta)\]\[ \hat{S}=f_s(I,\hat{v})\]\[ \hat{R}=f_r(I,\hat{v},\hat{S};\theta_r)\]\[ \hat{\ell}=f_{\ell}(I,\hat{v},\hat{S},\hat{R};\theta_{\ell}) \]
各项参数含义分析:
视角\(v\):利用给定图像预测视角参数,包含7个参数,分别式3D空间旋转角度,平移坐标和缩放因子。
形状\(S\):形状的预测取决于给定的图像和预测视角参数,利用预测的视角v,我们可以将图像在二维平面上与标准的视图进行对齐,经过网络输出形状系数,形状系数一共有228个参数。
反射率\(R\):反射率的预测不仅取决于给定的图像,还取决于预测的视角和形状,本文采用uv贴图作为网络输入来预测反射率
光照\(\ell\):以给定的图像、被照亮的纹理图和反射率的UV图为输入,得到光照参数,光照参数包含9个参数。
损失函数
通过一个人脸分割网络来识别像素是否属于人脸区域,用分割网络对人脸图片进行掩模处理,每张图片的像素都有一个掩码值\(M(i,j)\),若\(M(i,j)=1\)则该像素包含在重建过程中,否则不包括。光学度损失可表示如下:
\[ \mathcal{L}_{ph}=\varepsilon(I,S,R,v,\ell,M)=||M \otimes I - M \otimes \hat{I}||_1=||M \otimes I - M \otimes \hat{I}||_1 \]
\(||.||_1\)表示测量L1范数,\(\otimes\)表示element-wise乘法。
根据反射率对称性和一致性约束对上述的损失函数作了一定优化: \[ \mathcal{L}_{ph} = \frac{1}{N}\sum^{N}_{i=1,\xi_j=\xi_i}(\varepsilon(I_i,S_i,R_j,v_i,\ell_i,M_i)+\varepsilon(I_i,S_i,R^{\bowtie}_i,v_i,\ell_i,M_i)) \]
还有一个根据人脸2D关键点构造的损失和一个形状系数正则化损失,分别如下:
\[ \mathcal{L}_{kp} = \frac{1}{NN_{kp}}\sum^{N}_{i=1}\sum^{N_{kp}}_{j=1}||Q_i(k_j)-q_i(j)||_1 \]\[ \mathcal{L}_{rg} = \frac{1}{N}\sum^{N}_{i=1}||\alpha_i||^2_2 \]
整体损失函数 \[ \mathcal{L} = \mathcal{L}_{ph} + \lambda_1\mathcal{L}_{kp} + \lambda_2\mathcal{L}_{rg} \]