Authentic Volumetric Avatars from a Phone Scan
目录
摘要
创造出一个逼真级的人脸头像需要大量的面部捕捉数据,但是这种条件只有视觉特效企业才能做到,无法普及到大众群体。本文的工作就是利用手机捕捉数据来得到一个真实匹配人脸的头像。
不同于以往直接对整个人脸外观进行建模的方法,本文的方法仅使用少量的数据就可以应对各种人脸生成一个头像模型。
这个模型摒弃了会产生幻觉身份的低维潜在空间信息,相反,它使用了可以提取不同尺度person-specific信息的条件表示
本文方法的输出不仅是一个与人的面部形状和外观相匹配的高保真3D头像,而且还可以使用一个具有对注视方向的分离控制的共享全局表情空间来驱动人脸。
介绍
人脸是身份认证的重要属性,人脸外表,结构和姿态的细微变化都会降低人脸头像的重建质量。过去的方法为了解决这一问题都需要大量的数据驱动和预处理操作,损耗的算力和时间都是巨大的。
从有限的数据自动创建头像的核心挑战在于先验和验证之间的权衡。需要先验来补充有关人的外观,几何形状和运动的有限信息,这些信息可以以轻量级的方式获得。然而,尽管近年来取得了重大进展,但以高分辨率学习人脸的多种情况仍然具有挑战性。对分布的长尾进行建模,这对于捕获特定雀斑,纹身或疤痕等个人特质是必要的,可能需要具有更高维潜在空间的模型,因此,比目前用于训练此类模型的数据要多得多。
我们以前的架构是基于这样的观察,即面部外观和结构的长尾方面在于细节,最好直接从一个人的条件数据中提取,而不是从低维的身份嵌入中重建。早期方法从低维身份embeddings重建方法很快会陷入停滞,难以捕获到person-specific信息。我们的模型是一种超网络,它将用户中性面孔的数据作为输入,并以偏差图的形式为个性化解码器生成参数。
在这项工作中,我们通过消除对不存在的人产生幻觉的能力来打破先验和验证之间的权衡,相反,我们使用易于获得的真实人物的手机数据来适应。本文的方法分为3个要素:
- 在多视角观测下上百个人的视频数据里训练得到的普适性先验模型
- a registration technique for conditioning the model on a phone scan of the user’s neutral expression
- 一种逆向渲染方式去微调额外情感数据上的个性化人脸模型
创新点
Key Words: hypernetwork, inverse rendering
本文主要贡献如下:
- 一种用于产生逼真头像的系统,与以往方法相比,质量有大幅提高
- 一种新颖网络架构,网络模型鲁棒性很高。产生的头像拥有一致的对视角点,表情和注视方向分离控制的表情空间
- 逆向渲染策略,在给定的额外手机正面拍摄数据下,将头像的表情空间特征化于用户,同时保证视角点的泛化性和潜在空间的语义
方法
Method Overview
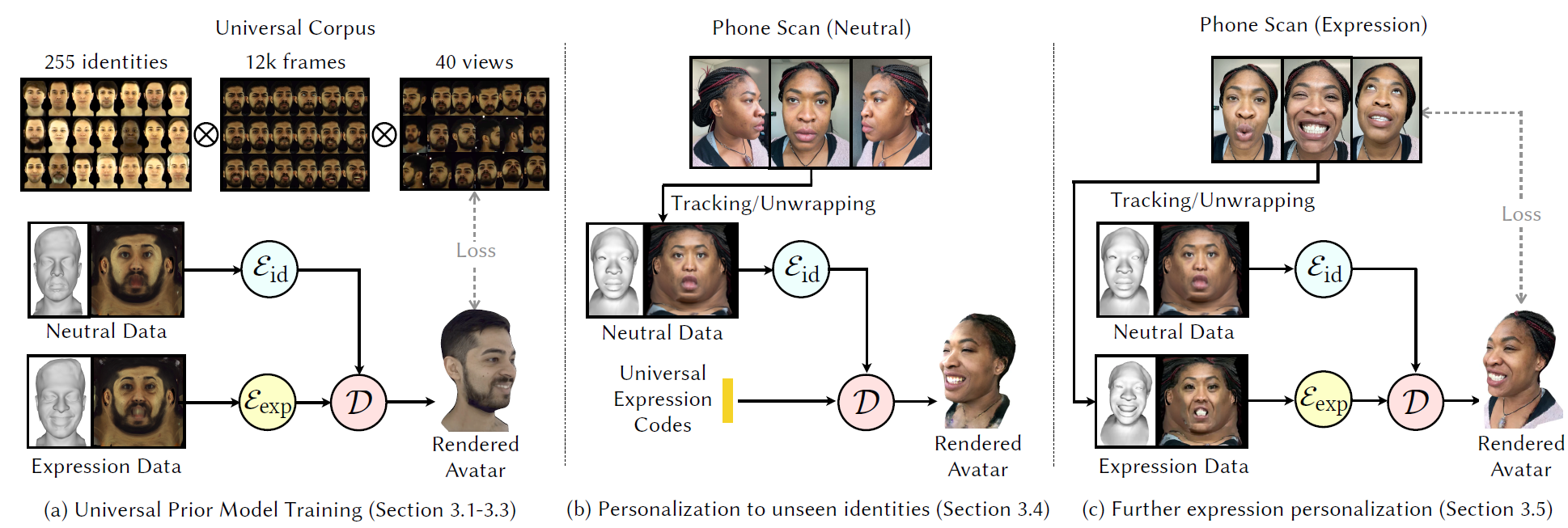
Universal Prior Model
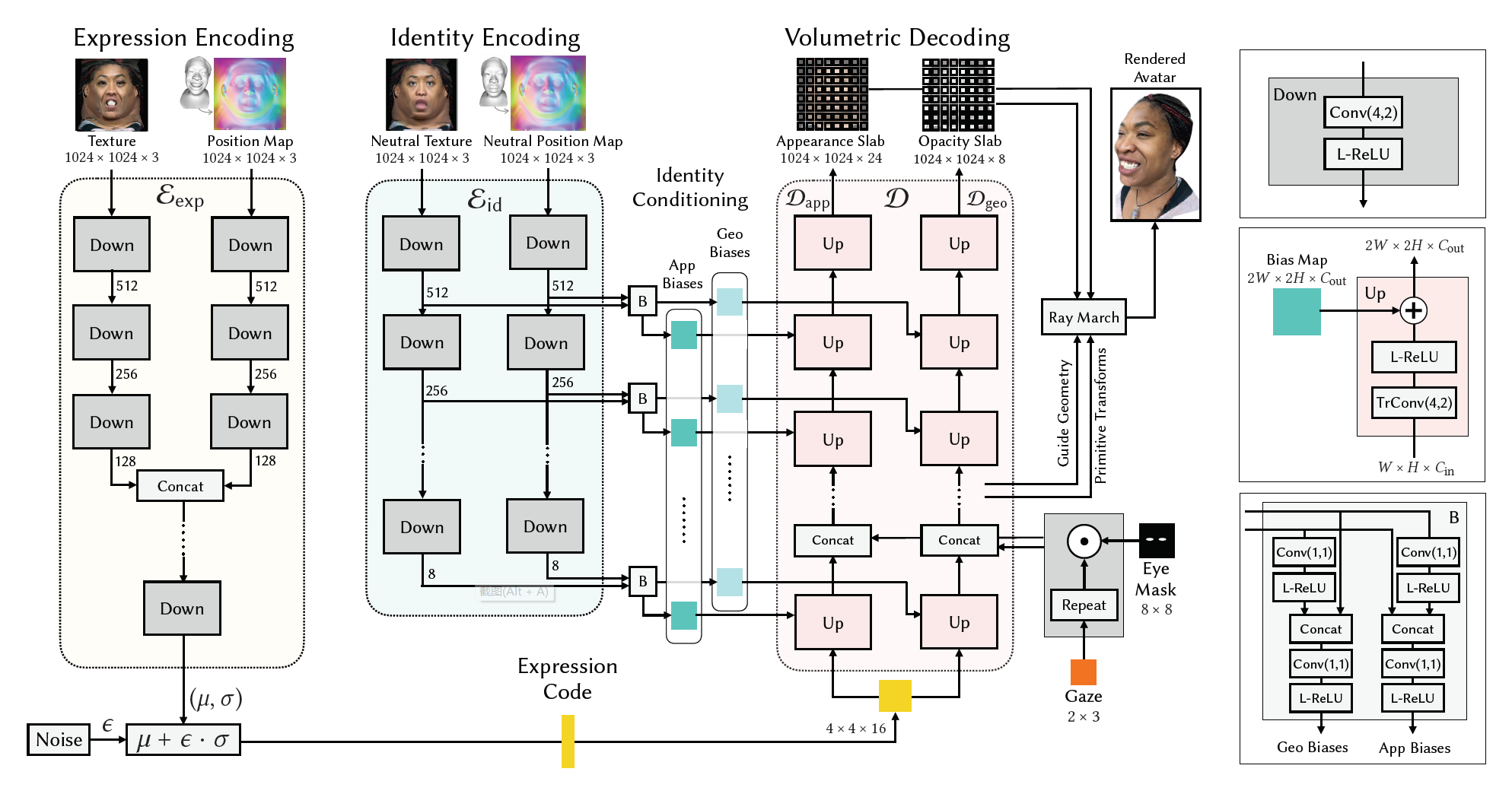
\[ e = \mathcal{E}_{exp}(\vartriangle{T_{exp}},\vartriangle{G_{exp}};\Phi_{exp}) \]\[ \Theta_{id} = \mathcal{E}_{id}(T_{neu},G_{neu};\Phi_{id}) \]\[ \mathcal{M} = \mathcal{D}(e,v,g;\Theta_{id},\Phi_{dec}) \]\[ \vartriangle{T_{exp}} = T_{exp} - T_{neu} \]\[ \vartriangle{G_{exp}} = G_{exp} - G_{neu} \]
\(e\)表示情感系数expression code;\(\Theta_{id}\)表示bias maps;\(\mathcal{M}\)表示volumetric primitives slabs,用于后续Ray March操作;\(\Phi_{exp} 、\Phi_{id}、\Phi_{dec}\)是可训练的参数,我认为是网络权重。
Dataset
跟踪网格(tracked meshes)的生成分为三个步骤:Capture Dome, Capture Script, Tracking Pipeline。
Capture Dome: 为了捕获面部表演的同步多视图视频,本文构建了一个多摄像机捕获系统。摄像机系统含有几十个彩色和单色摄像机,摄像机以4096*2668的分辨率拍摄,快门速度为2.222ms,每秒90帧。350个点光源均匀分布在整个结构中,以均匀地照亮参与者。
Capture Script: 捕获脚本的目标是在最短的时间内系统地引导参与者完成各种面部表情。参与者被要求完成以下练习:模仿65个不同的面部运动片段;执行自由形式的面部运动范围部分;向25个不同的方向看以表示不同的凝视角度;阅读50个语音平衡的句子。总共有255名参与者使用此捕获脚本的数据采集,并且每个参与者平均记录了12k个子采样帧,总共有310万帧图片。
Tracking Pipeline: 为了有效地生成超过 310 万帧的跟踪网格,我们实施了高度可扩展的两相方法。我们的方法可以独立处理每个帧,从而完全并行处理。在第一阶段,我们训练一个高覆盖率的地标探测器,产生一组320个地标,这些地标均匀分布在脸上,覆盖突出特征(如眼角)以及更均匀的区域(如脸颊和前额)。
Training and Losses
通用先验模型参数为\(\Phi=[\Phi_{exp},\Phi_{id},\Phi_{dec}]\)。优化的算法如下:
\[ \Phi^{*} = argmin \sum_{i\in{\mathcal{N}_{\mathcal{I}}}} \sum_{f\in{\mathcal{F}_{\mathcal{i}}}} \sum_{c\in{\mathcal{N}_{\mathcal{C}}}} \mathcal{L}_{total}(\Phi;\mathcal{I}_{f}^{i,c}) \]
\[ \mathcal{N}_{\mathcal{I}} : different{\ }identities \]
\[ \mathcal{N}_{\mathcal{F}_i} : frames \]
\[ \mathcal{N}_{\mathcal{C}} : different{\ }camera{\ }views \]
整体损失函数算式如下: \[ \mathcal{L}_{total}(\Phi;\mathcal{I}_{f}^{i,c}) = \mathcal{L}_{rec}(\Phi;\mathcal{I}_{f}^{i,c}) + \mathcal{L}_{mvp}(\Phi;\mathcal{I}_{f}^{i,c}) + \mathcal{L}_{seg}(\Phi) \]
重建损失函数算式如下: \[ \mathcal{L}_{rec}(\Phi;\mathcal{I}_p) = \mathcal{L}_{pho}(\Phi;\mathcal{I}_{f}^{i,c}) + \mathcal{L}_{vgg}(\Phi;\mathcal{I}_{f}^{i,c}) + \mathcal{L}_{gan}(\Phi;\mathcal{I}_{f}^{i,c}) \]\[ \mathcal{L}_{pho}(\Phi;\mathcal{I}_p) = \lambda_{pho} \frac{1}{\mathcal{N}_{\mathcal{P}}} \sum_{p \in{\mathcal{P}}} ||\mathcal{I}_{f}^{i,c}(p) - \tilde{\mathcal{I}}_{f}^{i,c}(p)||_1 \]
分割损失函数如下: \[ \mathcal{L}_{seg}(\Phi;\mathcal{I}_{p}) = \lambda_{seg} \frac{1}{\mathcal{N}_{\mathcal{P}}} \sum_{p \in{\mathcal{P}}} ||\mathcal{O}_{f}^{i,c}(p) - \mathcal{S}_{f}^{i,c}(p)||_1 \]
Conditioning Data Acquisition
要为用户重建逼真的头像,我们首先获取UPM所需的训练数据。对于捕获数据过程,要求用户在将手机从左到右,然后上下移动时保持固定的中性表情,以完全捕获整个头部,包括头发。
获取数据流程如下: 1. 利用iPhone12的深度相机对用户中性表情进行各角度拍摄; 2. 每张照片都检测出人脸landmarks; 3. 对照片进行分割,得到分割掩码和轮廓痕迹 4. 使用PCA模型,优化PCA系数,头部旋转角度,平移等参数,得到mesh 5. mesh经过unwarp得到texture 6. 利用之前得到的mesh和texture,渲染得到3D Face
Personalized Decoder Generation
Personalize Reconstruct流程:将获取到的mesh转化成geometry image,geometry image和neutral texture一并输入到UPM,最后渲染输出avatar。
目前存在弊端就是输入数据存在domain gap,其一是训练UPM的数据及实在静态且亮度均匀的环境下采集的,而手机数据是在自然环境光下获取的,其二是由于物理限制,手机捕获数据仅覆盖头部的前半球面样貌。
为了弥补这个差距,采用两步措施。一是手机面部数据的mesh拟合算法应用到实验室采集数据上,用离散个别相机照片等效于手持相机拍摄的效果;二是纹理归一化,选取误差最小的图片。
Finetuning a Personalized Decoder
\[ \mathcal{L}_{ref}(\Phi;\mathcal{I}_{f}) = \mathcal{L}_{rec}(\Phi;\mathcal{I}_{f}) + \mathcal{L}_{hole}(\Phi;\mathcal{I}_{f}) + \mathcal{L}_{seg}(\Phi;\mathcal{I}_{f}) \]\[ \mathcal{L}_{hole}(\Phi;\mathcal{I}_{f}) = \lambda_{hole}||max(\mathcal{T}_{f} - \mathcal{O}_{f},0)·\mathcal{T}_{f}||_1 \]
\(\mathcal{I}_{f}\): expression frames; \(\mathcal{T}_{f}\): rendered mask; \(\mathcal{O}_{f}\): the integrated opacity computed during ray marching
局限性
- 需要大量时间处理数据,数据不合适会造成过拟合现象。
- 用于构建UPM的数据与真实世界数据之间的域差距。
- 无法重建出完整身体,发型上的重构仍有待改进,包含眼镜的人脸重建效果有待改进。